Evaluation of the quality of a medical neural network
Evaluation of the quality of a medical neural network is an important stage, without which it is impossible to understand whether the technology is applicable in real clinical practice. In the article, we will talk about the main methods for evaluating the quality of models based on machine learning in the field of computer vision.
Sensitivity, specificity, accuracy
Let's consider a typical example of a computer vision model: a digital medical image uploads to the neural network, a binary conclusion should be made towards it (there is cancer or there is no cancer). Neural network predictions can be divided into four categories.
- A truly positive result — ( TP) - the model says that there is cancer, and it really is in the image.
- A faulty positive (FP) — the model says that there is cancer, but in fact, there is no cancer.
- A truly negative (TN) — the model says that there is no cancer, and there really is no cancer.
- A faulty negative (FN) — the model says that there is no cancer, but in fact it is.
Often the results of the classification model are presented in a matrix:

Based on these results, the primary medical metrics of the quality of models with artificial intelligence are formed: sensitivity, specificity, and accuracy. Sensitivity (Se, Sensitivity/Recall) is the ability of an AI-based model to detect pathologies if they exist. Se = TP / (TP+FN) * 100%. Specificity (Sp, Specificity) — the ability of the model not to give positive results about the existence of a disease if it is absent. Sp = TN / (TN+FP) * 100% Accuracy — Ac, Accuracy) is the ability of the model to give the correct result towards the total number of examinations. Ac = (TP+FN) / all examinations*100% At first sight, it may seem that the last metric (accuracy) is the most indicative. However, it is not very informative when evaluating the model using datasets with different class balances. Let's assume that our sample consists of 100 patients, 90 of them are healthy, 10 are sick. The neural network identified 78 healthy patients (and missed 12), identified 8 sick patients (and missed 2). We count the accuracy: Ac = (78+8) / 100 = 86%. But if the neural network simply classified all patients as healthy, the accuracy rate would be 90%. And this is despite the fact that the model, in this case, does not have any predictive power and is generally useless because it is important for us to find exactly sick patients, but not to mark everyone as healthy. That is why, when changing or updating the model, all metrics should be measured using the same dataset with the same class balance. Thus, when solving this problem (detection of pathologies), sensitivity and specificity are metrics that have different goals, and a compromise must be found between them. If the first metric is aimed at minimizing the risk of missing a pathology, the second is aimed at reducing the number of patients sent for additional examination. Moreover, under different operating scenarios (for example, during screening and diagnostics), it is possible to make additional adjustments to the system, which will provide the accuracy metrics necessary for this scenario.
Is AUC the queen of metrics?
Nevertheless, the key metric for evaluating the predictive power of the final model for solving the classification problem is ROC AUC (Area Under Receiver Operating Characteristic Curve). Other metrics, such as sensitivity and specificity, will depend on it. To understand what AUC is, you first need to understand what the ROC curve is. It is a graph of two parameters — the truly positive and faulty positive rate (TPR and FPR respectively). Here's how they are calculated: TPR = TP / (TP + FN) FPR = FP / (FP + TN) The ROC curve looks like this:
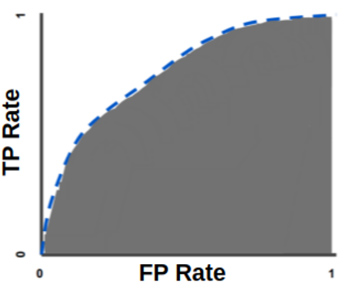
The AUC metric on this graph will represent the coverage area of the space under the ROC curve. The greater the curvature of this curve, the greater the predictive power of the classification model. Let's take an example. Let's say you created a neural network for coinflip predictions - on which side the coin will fall. Heads or tails are random events, the probability of each of them is 50%. The AUC for evaluating your neural network, in this case, will be measured from 0.5 to 1 — where 0.5 means that the neural network makes absolutely random predictions, and 1 means that all its predictions are correct. The goal of researchers in solving the classification problem is to maximize this metric because with increasing AUC values, errors in the form of faulty negative and faulty positive results occur less and less often.
Which AUC can be considered good?
There is no exact answer to this question — everything depends on the type of task, the quantity, and quality of data, the elaboration of the solution of the problem in scientific circles, and other factors. For example, already at the first stages of training a neural network in classifying of examinations according to the principle "there is oncology / there is no oncology", it becomes clear that the model will show significantly higher AUC values on lung X-rays than on mammography. In addition, the field of mammography is much less developed in machine learning than lung X-rays. Despite this, it is still possible to set the lowest border of the permissible AUC for artificial intelligence in medical diagnostics: 0.8. The use of a neural network in clinical practice makes sense only if this minimum value is reached.
What else is important for evaluating the model?
As soon as there is a need to evaluate a neural network, there is a question about its testing on a sample. And since medical data is very specific, and model errors can lead to really bad consequences in the treatment of a patient, for maximum transparency of the assessment some points should be followed
- Localization of objects and other information should be gained as a result of the cross-marking mechanism and verified based on anamnesis. Cross-marking is a process in which several doctors consistently, independently of each other mark objects of interest on the same image
- The examinations of which the test sample consists, if possible/applicable, should be verified by biopsy.
- This "golden dataset" must be of adequate size. For example, if a neural network was trained on 10,000 images, it would be strange to evaluate its metrics on a sample of 100 examinations. And vice versa — it will be inefficient to train a neural network for 1,000 examinations and then test it for 1,000 examinations that did not participate in the training.
Thus, for an adequate evaluation of a medical neural network, it is not enough just to know the basic metrics — you need to take into account the influence of many factors specific to a particular field of medicine. That is why the participation of highly qualified doctors is required not only in the training but also in the evaluation of such artificial intelligence systems.