- Главная
- РешенияМаммография
Сервис интеллектуального анализа и интерпретации маммограмм
Флюорография и рентген области грудной клеткиСервис для выявления заболеваний органов грудной клетки
Комплексный сервис для анализа КТ органов грудной клеткиСервис для выявления признаков 10 патологий
Компьютерная томография головного мозгаСервис для выявления признаков кровоизлияний в головной мозг
- Новости
- О нас
- Контакты
Как оценить качество медицинских нейросетей?
Оценка качества медицинской нейронной сети — важный этап, без которого невозможно понять, применима ли технология в реальной клинической практике. В статье расскажем об основных методах оценки качества моделей на базе машинного обучения в области компьютерного зрения.
Чувствительность, специфичность, точность
Рассмотрим типичный пример модели компьютерного зрения: на вход нейронной сети попадает цифровое медицинское изображение, относительно которого должен быть сделан бинарный вывод — есть рак или нет рака. Прогнозы нейросети можно разделить на четыре категории.
- Истинно положительный результат (ИП) — модель говорит, что рак есть, и он действительно есть на изображении.
- Ложно положительный (ЛП) — модель говорит, что рак есть, но на самом деле его нет.
- Истинно отрицательный (ИО) — модель говорит, что рака нет, и его действительно нет.
- Ложно отрицательный (ЛО) — модель говорит, что рака нет, но на самом деле он есть.
Часто результаты классификационной модели представляются в виде матрицы:

Исходя из этих результатов формируются первичные медицинские метрики качества моделей на базе искусственного интеллекта: чувствительность, специфичность и точность.
Чувствительность (Se, Sensitivity/Recall) — это способность модели на базе ИИ выявлять патологии при их наличии. Se = ИП / (ИП+ЛО) * 100%.
Специфичность (Sp, Specificity) — способность модели не давать положительных результатов о наличии заболевания при его отсутствии. Sp = ИО / (ИО+ЛП) * 100%
Точность (Ac, Accuracy) — это способность модели давать правильный результат относительно общего количества исследований. Ac = (ИП+ИО) / все исследования*100%
На первый взгляд может показаться, что последняя метрика (точность) является наиболее показательной. Однако она не очень информативна при оценке модели на наборах данных (датасетах) с разным балансом классов.
Предположим, наша выборка состоит из 100 пациентов, 90 из них здоровы, 10 больны. Нейронная сеть выявила 78 здоровых пациентов (и пропустила 12), выявила 8 больных (и пропустила 2). Считаем точность: Ac = (78+8) / 100 = 86%.
Но если бы нейронная сеть просто отнесла всех пациентов к здоровым, показатель точности был бы 90%. И это несмотря на то, что модель в данном случае не обладает никакой предсказательной силой и в целом бесполезна — так как нам важно находить именно больных пациентов, а не отмечать всех как здоровых.
Именно поэтому при изменении или обновлении модели все метрики должны измеряться на одном и том же датасете с одним и тем же балансом классов.
Таким образом, при решении данной задачи (детекция патологий) чувствительность и специфичность являются метриками, имеющими разные цели, и между ними нужно найти компромисс. Если первая метрика направлена на минимизацию риска пропуска патологии, то вторая направлена на сокращение количества отправленных на дополнительное обследование пациентов. Причём при разных сценариях работы (например, при скрининге и при диагностике) можно производить донастройку системы, что обеспечит необходимые для данного сценария метрики точности.
AUC — королева метрик?
И всё же ключевой метрикой оценки предиктивной (предсказательной) силы итоговой модели для решения задачи классификации является ROC AUC ( Area Under Receiver Operating Characteristic Curve). Название метрики переводится с английского как «площадь под кривой». Остальные метрики, такие как чувствительность и специфичность, будут зависеть от неё.
Чтобы понять, что такое AUC, нужно сперва разобраться с тем, что такое кривая ROC. Она представляет собой график двух параметров — истинно положительной и ложно положительной скорости (TPR и FPR соответственно).
Вот как они вычисляются:
TPR = ИП / (ИП + ЛО)FPR = ЛП / (ЛП + ИО)
Кривая ROC выглядит следующим образом:
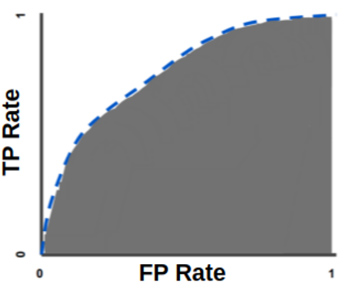
Метрика AUC на этом графике будет представлять собой площадь покрытия пространства под ROC-кривой. Чем больше изгиб этой кривой, тем большую предиктивную силу имеет классификационная модель.
Рассмотрим на примере. Допустим, вы подбрасываете монетку и создали нейронную сеть для предсказания того, какой стороной она упадёт. Выпадение орла или выпадение решки являются случайными событиями, вероятность каждого из них равна 50%. AUC для оценки вашей нейросети в данном случае будет измеряться от 0,5 до 1 — где 0,5 означает, что нейросеть даёт абсолютно случайные предсказания, а 1 означает, что все её прогнозы верны.
Цель исследователей при решении задачи классификации — максимизировать эту метрику, так как при повышении значений AUC ошибки в виде ложно отрицательных и ложно положительных результатов происходят всё реже и реже.
Какой AUC можно считать хорошим?
Однозначного ответа на этот вопрос не существует — всё зависит от вида задачи, количества и качества данных, проработанности решения задачи в научных кругах и других факторов.
Например, уже на первых этапах обучения нейросети для классификации исследований по принципу «есть онкология / нет онкологии» становится ясно, что модель будет показывать значительно более высокие показатели AUC на рентгене лёгких, чем на маммографии. Это связано, в первую очередь, с тем, что данных по маммографии не просто меньше, а кратно меньше, чем данных по рентгену лёгких. К тому же, область маммографии значительно менее проработана в машинном обучении, чем рентген лёгких.
Несмотря на это, всё же можно обозначить нижнюю границу допустимости AUC для искусственного интеллекта в медицинской диагностике: 0,8. Применение нейросети в клинической практике имеет смысл только при достижении этого минимального значения.
Что ещё важно для оценки модели?
Как только появляется необходимость оценки нейронной сети, сразу встаёт вопрос о проверке её на какой-либо выборке. И поскольку медицинские данные весьма специфичны, а ошибки модели могут привести к реальным нежелательным последствиям при лечении пациента, для максимальной прозрачности оценки необходимо соблюдать важные критерии.
Таким образом, для адекватной оценки медицинской нейронной сети недостаточно просто знать основные метрики — нужно учитывать влияние множества факторов, специфичных для конкретной области медицины. Именно поэтому не только в обучении, но и в оценке таких систем искусственного интеллекта требуется участие высококвалифицированных врачей.